고정 헤더 영역
상세 컨텐츠
본문
최근에 딥시크 OCR2가 나와서 뭘 좀 해보고 싶은게 있어서 보던 중 새로운 OCR 모델이 더 나아보여서 소개합니다
https://huggingface.co/zai-org/GLM-OCR
zai-org/GLM-OCR · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
https://github.com/zai-org/GLM-OCR
GitHub - zai-org/GLM-OCR: GLM-OCR: Accurate × Fast × Comprehensive
GLM-OCR: Accurate × Fast × Comprehensive. Contribute to zai-org/GLM-OCR development by creating an account on GitHub.
github.com
GLM-OCR은 멀티모달 OCR 모델입니다. 이 모델은 기본적으로 GLM-V 인코더-디코더 아키텍처를 기반으로 하며, 대규모 이미지-텍스트 데이터로 사전 학습된 CogViT visual 인코더와 0.5B language 디코더를 결합하여 총 0.9B로 구현해낸 것이 특징입니다. Deepseek-OCR2가 3B의 크기를 자랑했는데 바로 0.9B로 더 나은 성능을 낸다고 하니
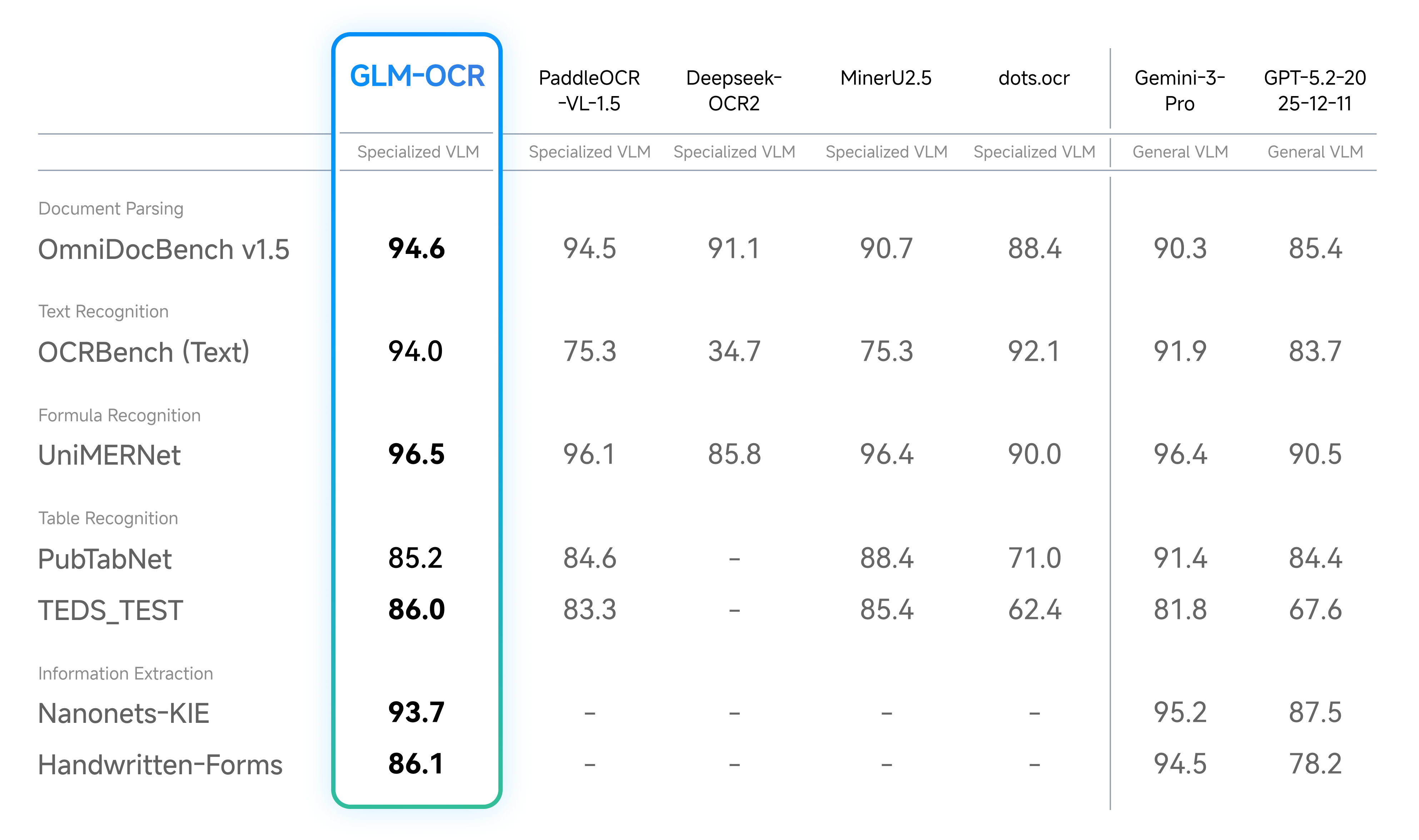
실제 성능 지표를 살펴보면, GLM-OCR은 OmniDocBench V1.5에서 94.62점을 기록하며 종합 1위라고 하구요, 수식 및 표 인식, 정보 추출 등 문서 이해 벤치마크입니다

Real-world benchmark에서도 재미나이나 gpt와 비슷한 성능인건 좀 놀랍습니다

속도 테스트 결과에서도 PDF 문서는 초당 1.86페이지, 이미지는 초당 0.67개를 처리하며 경쟁 모델 대비 압도적인 효율성을 증명했습니다만 이러한 벤치마크는 자신에게 유리한 하드웨어를 선정하는 경우가 많으므로
사용자는 목적에 따라 크게 두 가지 시나리오로 이 모델을 활용할 수 있습니다. 첫 번째는 문서 파싱(Document Parsing)으로, 텍스트, 수식, 표 인식을 위한 전용 프롬프트를 통해 문서의 원시 콘텐츠를 추출하는 방식입니다. 두 번째는 정보 추출(Information Extraction) 시나리오인데, 사용자가 정의한 특정 JSON 스키마를 프롬프트에 포함하면 모델이 해당 형식에 맞춰 구조화된 데이터를 정확하게 출력해 줍니다.
GLM-OCR은 오픈소스로 제공됩니다. 제공되는 SDK와 추론 툴체인으로 모델을 호출하거나 기존 생산 라인에 손쉽게 통합할 수 있습니다. 0.9B라 다른 프로그램에 쑤셔넣기도 부담이 적을 것 같습니다. 딥시크처럼 paper형태로 딱 나오지는 않아서 공개된 정보가 많지는 않습니다. 최근들어 OCR 관련한 모델들이 많이 나오네요
깃허브에서 다양한 환경에서 테스트할 수 있도롣 상세한 설명이 나와있습니다. 마침 개념정리 pdf 하나가 텍스트로 되어있지 않아서 테스트해보기로 했습니다. 사실 사진도 테스트를 해보았는데 애플 기본에서 사진에서 글씨를 추출하다보니 제대로 되었는지 아닌지 알아보기 어렵습니다.
간단하게 mlx-vlm을 사용해서 해보았습니다. 설명이 아주 상세합니다
https://github.com/zai-org/GLM-OCR/blob/main/examples/mlx-deploy/README.md
GLM-OCR/examples/mlx-deploy/README.md at main · zai-org/GLM-OCR
GLM-OCR: Accurate × Fast × Comprehensive. Contribute to zai-org/GLM-OCR development by creating an account on GitHub.
github.com


정상적으로 실행 중인 상태입니다. 맥북에어 M2 기본형에서 구동시에 메모리를 4기가정도만 소요합니다. 생각보다 CPU 사용량도 많지 않네요 많아도 40% 이상을 점유하지 않고 20%대를 유지하는 모습입니다.

테스트를 해본 pdf 파일은 개념정리 파일로 한글로 대부분 채워진 102장 입니다. pdf ocr을 잘한다고 하는 편인 서드파티 프로그램을 사용했을 때는 검색도 제대로 안되는 좀 실망스러운 결과였습니다. 문서를 그대로 pdf로 저장한거라 그렇게 어렵지 않았을 것인데 말입니다
결과는
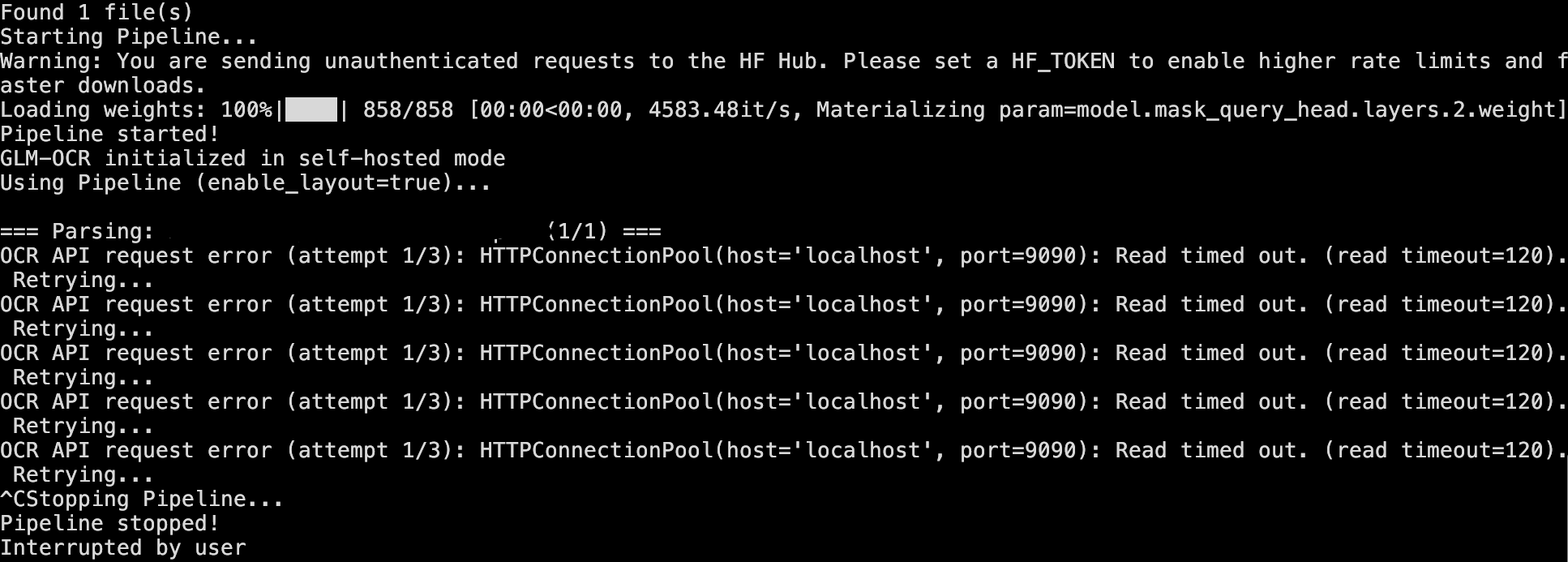
뻗어버리네요.... 일단 테스트를 해보기 위해서 10장만 테스트를 한 결과 성공은 했습니다만 자신들의 성능으로 주장한 대로 라면 20초 컷이 나야하지만 한 10장을 ocr하는데 4분 정도 걸렸습니다. 페이지당 1.8초 당연히 저건 gpu에서 돌린 결과겠죠
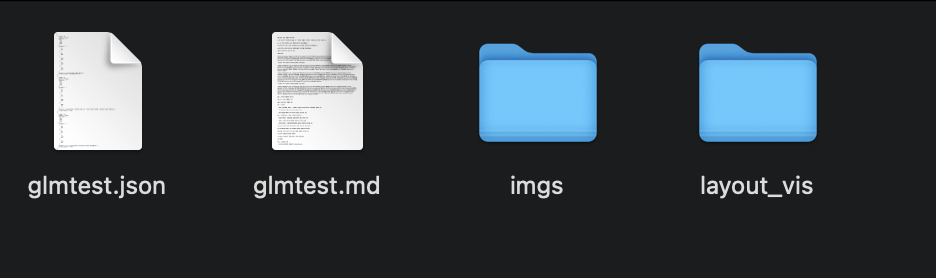
조금 안타깝지만 pdf를 ocr하면 json과 이미지로 분리되서 나와서 후처리 과정이 필요합니다. 어쨋든 이것도 모델이다보니 config에서 프롬프트를 입력할 수 있는데 프롬프트에 따라서 인식률이 좀 달라질까요? 혹은 한글로써의 최적화가 나아질까요?

댓글 영역